






统计学
总览
统计可以推测趋势和规律,说明自然和人文现象。
很多人认为统计学是一种科学的数学分支,是关于收集、分析、解释、陈述数据的科学。 另一些人认为它是数学的一个分支,因为统计学是关于收集解释数据的。 由于它基于观测、重视应用,统计学常被看作是一门独特的数学科学,而不是一个数学分支。 很多统计学都不是数学的:如确保所收集来的数据能得出有效的结论;将数据编码、存档以使得信息得以保存,可以在国际上进行比对;汇报结果、总结数据,以便统计员可以明白它们的意思;采取必要措施,保护数据来源对象的隐私。
统计学家通过专门的试验设计和调查样本来提升数据质量。统计学自身也为数据的概率模型提供了预测工具。统计学在其他学术科目上得到了广泛的应用,如自然科学、社会科学、政府、商业等。统计顾问可以帮助没有入户调查经验组织与公司进行问卷研究。
总结叙述收集来的数据被称之为描述统计学。这在进行实验研究信息交流中十分有用。另外,从数据的分布上也可以得出观测上的随机性和不确定性。
将数据中的数据模型化,计算它的概率并且做出对于母群体的推论被称之为推论统计学。推论是科学进步的重要因素,因为它可能从随机变量中得出数据的结论。推论统计学将命题进行更深入的研究,将结果进行检测。这些都是科学方式的一部分。描述统计学和对新数据的分析更倾向于提供更多的信息,逼近命题所述的真理。
“应用统计学”包括描述统计学和推论统计学中的应用成分。 理论统计学则注重统计推论背后的逻辑证明,以及数理统计学。数理统计学不但包括推导估测推论法的概率分布,还包括了计算统计和试验设计。
统计学与概率论联系紧密,并常以后者为理论基础。简单地讲,两者不同点在于概率论从母群体中推导出样本的概率。统计推论则正好相反——从小的样本中得出大的母群体的信息。
统计学的历史
统计手法最早可以追溯至公元前5世纪。最早的统计著作来自公元9世纪的《密码破译》( Manuscript on Deciphering Cryptographic Messages )一书,由阿拉伯人肯迪编著。在书中,肯迪详细记录了如何使用统计数据和频率分析进行密码破译。根据沙特阿拉伯工程师易卜拉欣·阿凯笛(Ibrahim Al-Kadi)的说法,统计学和密码学分析便如此一同诞生了
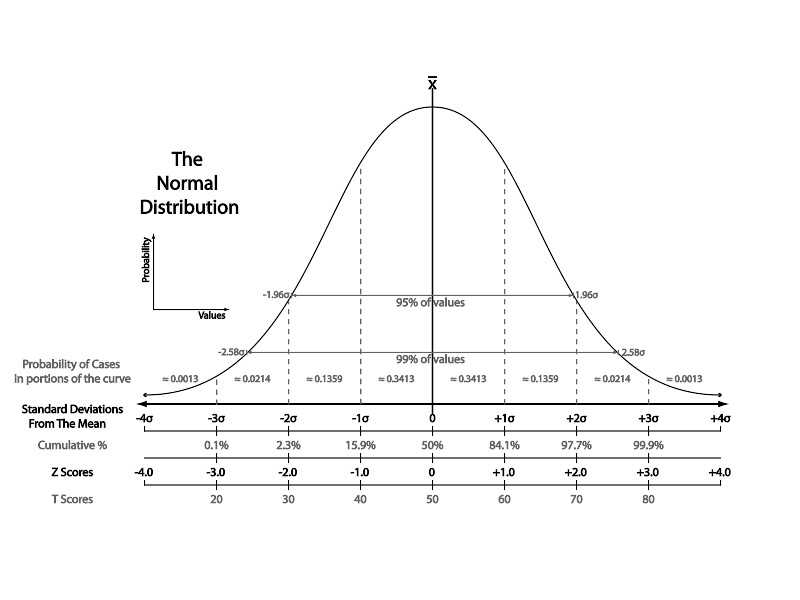
常态分配的钟型曲线的图
佛罗伦萨银行家、执政官乔瓦尼·维伦(Giovanni Villani)编订了佛罗伦萨14世纪历史书籍 Nuova Cronica ,包括了如人口、法令、商贸、教育、宗教场所在内的统计数据,被誉之为历史上统计学入门的第一本书。 一些学者将1663年约翰·格兰特根据死亡率统计表编订出版的《自然与政治观察》( Natural and Political Observations )一书定格为统计学的诞生。
统计学的英语词statistics是源于现代拉丁语statisticum collegium(国会)以及意大利语statista(国民或政治家)。德语Statistik,最早是由Gottfried Achenwall(1749)所使用,代表对国家的数据进行分析的学问,也就是“研究国家的科学”。在十九世纪统计学在广泛的数据以及数据中探究其意义,并且由John Sinclair引进到英语世界。
统计学的初衷是作为政府(通常是中央政府)以及管理层次结构的工具。它大量通过国家以及国际统计服务搜集国家以及本土的数据。另外依照各方面,普查则提供关母体的信息。统计背后牵涉到更多数学导向的领域,如概率,或是从经验科学(特别在天文学)中获得的经验证据设置估计参数。在今日的世界里统计已经被使用在不仅仅是国家或政府的事务,更延伸到商业,自然以及社会科学,医疗等甚至更多方面。因为统计学拥有深厚的历史以及广泛的应用性,统计学通常不只被认为是数学所处理的对象,而是与数学本身的哲学定义与意义有密切的关系。许多知名的大学拥有独立的数理统计学系。统计学也在如心理学,教育学以及公共卫生学系中被视为是一门主科。
统计学的数学基础创建在17世纪布莱兹·帕斯卡和皮埃尔·德·费马发展的概率论上。概率论从研究几率得来。最小二乘法由卡尔·弗里德里希·高斯于1794年第一次得出。现代计算机可以进行更大尺度的统计运算,生成了许多无法用人工计算的新公式。
统计学的观念
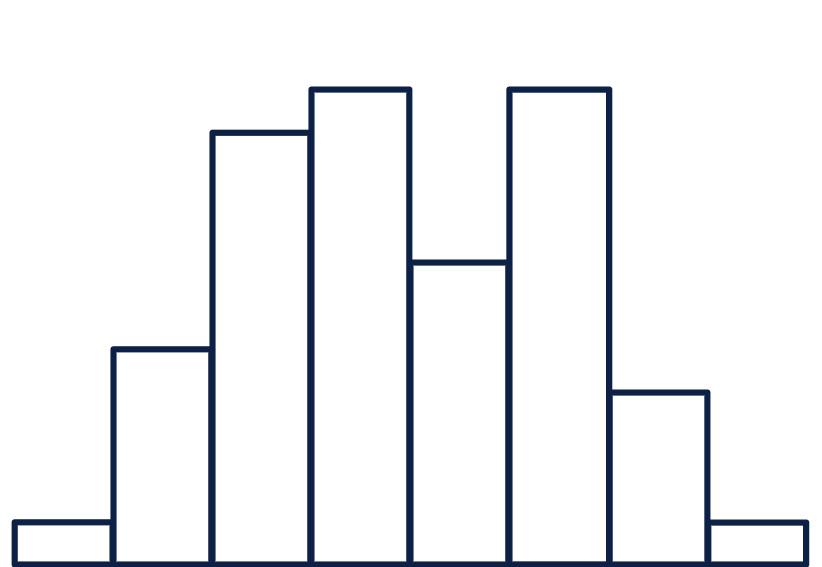
费舍尔鸢尾花数据集之中杂色鸢尾花萼片宽度数据的分布直方图
为了将统计学应用到科学、工业以及社会问题上,我们由研究母群体开始。这可能是一个国家的人民,石头中的水晶,或者是某家特定工厂所生产的商品。一个母群体甚至可能由许多次同样的观察程序所组成;由这种数据搜集所组成的母群体我们称它叫时间序列。
为了实际的理由,我们选择研究母群体的子集代替研究母群体的每一笔数据,这个子集称做样本。以某种经验设计实验所搜集的样本叫做数据。数据是统计分析的对象,并且被用做两种相关的用途:描述和推论。
描述统计学处理有关叙述的问题:是否可以摘要的说明数据的情形,不论是以数学或是图片表现,以用来代表母群体的性质?基础的数学描述包括了平均数和标准差等。图像的摘要则包含了许多种的表和图。主要是就说明数据的集中和离散情形。
推论统计学被用来将数据中的数据模型化,计算它的概率并且做出对于母群体的推论。这个推论可能以对/错问题的答案所呈现(假设检定),对于数字特征量的估计(估计),对于未来观察的预测,关系性的预测(相关性),或是将关系模型化(回归)。其他的模型化技术包括变异数分析(ANOVA),时间序列(time series analysis),以及数据挖掘(data mining)。
相关的观念特别值得被拿出来讨论。对于数据集合的统计分析可能显示两个变量(母群体中的两种性质)倾向于一起变动,好像它们是相连的一样。举例来说,对于人收入和死亡年龄的研究期刊可能会发现穷人比起富人平均来说倾向拥有较短的生命。这两个变量被称做相关的。但是实际上,我们不能直接推论这两个变量中有因果关系;参见相关性推论因果关系(逻辑谬误)。
如果样本足以代表母群体的,那么由样本所做的推论和结论可以被引申到整个母群体之上。最大的问题在于决定样本是否足以代表整个母群体。统计学提供了许多方法来估计和修正样本和搜集数据过程中的随机性(误差),如同上面所提到的通过经验所设计的实验。参见实验设计。
要了解随机性或是概率必须具备基本的数学观念。数理统计(通常又叫做统计理论)是应用数学的分支,它使用概率论来分析并且验证统计的理论基础。
任何统计方法是有效的只有当这个系统或是所讨论的母群体满足方法论的基本假设。误用统计学可能会导致描述面或是推论面严重的错误,这个错误可能会影响社会政策,医疗实践以及桥梁或是核能发电项目结构的可靠性。
即使统计学被正确的应用,结果对于不是专家的人来说可能会难以陈述。一些统计科学的结果对于大众而言相当费解。举例来说,统计数据中显著的改变可能是由样本的随机变量所导致,但是这个显著性可能与大众而言难以理解。另外,某些统计学分析(尤其当涉及概率论时)得出的结论可能非常违悖一般人的直觉,如蒙提霍尔问题。人们(甚至包括一些科学家)往往需要统计的技巧(或怀疑)才能理解其正确性。
统计方法
实验与观察性研究
统计研究中的共同目标是分析因果关系,具体来讲就是从预估数据变化中得出结论,或是研究自变量与因变量之间的关系。因果统计研究主要有两种:实验研究和观察研究。在两种研究中,自变量改变对因变量所造成的影响可以被观测到。两种实验间的不同在于实验时如何进行的。两种实验都很厉害。实验研究包括将系统尺度进行研究、操纵系统、使用更多的尺度进行同样的实验来确定操作是否改变了尺度的值。与之相对的是观察研究,观察研究不包括实验性操作。在此,数据被收集,预估数据与回复数据间的相关系数被研究。
实验研究
统计实验的基本步骤如下:
设立研究计划,包括找到代表研究项目的数据,使用如下信息:根据处理效应进行初步预估,备用假说,预估实验变率。对实验目标的选择和道德上的考虑也是必不可少的。统计学家推荐实验(至少)应与另一个相同标准、不同项目的参照组进行对比,以减少偏差。
试验设计,使用区组变量来减少干扰变量的影响,将对象进行随机处理,消除估算处理效用与实验误差中的偏差。在此阶段,实验参与者和统计学家填写 实验草案 ,并依此指导实验进程,对实验数据的原始分析进行细化。
根据实验草案进行实验、方差分析。
在第二次分析中进一步解析数据,为进一步研究提出新假说。
汇报研究结果并将其存档。
对人类行为的实验研究应该多加谨慎。著名的霍桑效应在西方电器公司(Western Electric)位于伊利诺伊州的霍桑工厂(Hawthorne Works)进行心理学实验,研究工作环境改变对生产率的影响。研究人员尝试增强照明,观察它是否有助于提高流水线工人的生产率。研究人员首先检测了工厂的生产率,尔后改变车间的照明强度,观察结果。结果是生产率在实验环境下的确提升了。然而,该实验因其流程误差在今天饱受批评,特别是实验缺乏参照组和双盲。霍桑效应指仅从观测来得出结论。该实验中生产率的提升不是因为照明强度的改变,而是因为工人们发觉他们被围观了。
观察研究
观察研究的具体例子是研究吸烟与肺癌之间的相关系数。这种研究常用调查来收集所需信息的观测结果,并对其进行统计分析。在本案例中,研究人员会收集吸烟和不吸烟者的观察数据,进行病例对照研究,然后观察每组中肺癌患者的数量。
测量的尺度
根据Stevens(1951)对数字的尺度分类,统计学一共有四种测量的尺度或是四种测量的方式。这四种测量(名目、顺序、等距、等比)在统计过程中各具有不等的实用性。等比尺度(Ratio measurements)拥有零值及数据间的距离是相等被定义的;等距尺度(Interval measurements)数据间的距离是相等被定义的,但是它的零值并非绝对的无,而是自行定义的(如智力或温度的测量);顺序尺度(Ordinal measurements)的意义并非表现在其值而是在其顺序之上;名目尺度(Nominal measurements)的测量值则不具量的意义。
统计术语
零假设
对统计信息的解释时常涉及到构建零假设,在该假设中,所有因素对变量都不起任何作用。
对新手来说最佳的比喻就是法庭窘境了。零假设H 0 认为被告是清白的,而备择假设H 1 则认为被告有罪。起诉是因为怀疑被告有罪。H 0 (现状)与H 1 对立并且被认可,除非H 1 被“超过合理质疑”的证据证伪。然而,“无法排除H 0 ”并不能代表被告清白,只是说证据无法将其定罪。所以,陪审团没有必要在H 0 “无法推翻”的情况下将其“接受”。当零假设无法被“证明”时,可以通过强度检测判断假设是否近似成立,即进行第二型错误检测。
误差
在零假设中存在两种基本误差:
第一型错误中零假设被错误地证伪,得出测试结果为“假阳性”。
第二型错误中零假设没有被及时排除,母群体中的实际差异被错误判断为“假阴性”。
当对样本的个体观察偏离了中心数据,如样本或母群体平均数,误差就出现了。许多统计方法尝试将中位数乘法的误差最小化,这种方法被称之为“最小二乘法”。
生成统计数据的过程也会产生误差。很多类似误差被是随机(噪音)性的,或是系统(偏倚)性的。但很多其他类型的重大误差(如疏忽:分析员把单位填错了)也是不容忽视的。
区间估算
许多时候研究只观察母群体的样本部分,所以结果并不能完全代表整个母群体。任何来自样本的估算只能得到母群体的近似值。置信区间是统计学家用来表述样本结果离整个母群体真实数值之间的差距。这常被表述为95%置信区间。形式上,数值为95%置信区间意味着如果在同样情况下重复样本分析(这回生成不同的数据集),95%的区间会得出匹配(母群体)情况的实际结果。这并不意味着真实数值的概率也在95%置信区间之内。从频率论的角度来说,这样的说法毫无意义,因为真实数值不是一个随机变量。真实数值要么在,要么不再给定的区间里。然而,任何数据在被抽取样本,设计置信区间之前,将要被计算的区间确实有95%的概率能代表真实数值:在这一点上,区间的极限仍然是有待被观测的随机变量。利用贝叶斯统计置信区间可以得出区间包涵真实数值的概率:这种方法对“概率”有另一种解释,即贝叶斯概率。
显著性差异
对于给出的问题,统计学很少回答简单的是或否。它的解释常常是以统计的显著性差异出现,汇报可以将零假设精确证伪的概率值(这也被称作是p值、假定值)。
显著性差异并不一定代表所有的结果在现实世界里都很显著。例如对药品的研究得出其具有统计的显著性差异,但是实际上药品可能毫无益处。这样的药品不会很有效地帮助病人康复。
由于假设检验中可能更加偏向于某一假设(如零假设),在大尺度研究中可能会对微小差异过度夸张,因此这中方法受到批评。显著性差异所得出的重大差额并不一定在现实中有意义,但是我们仍旧可以据此设计出相应的实验。
在报告假设是否被证伪时,一些方法不仅仅报告显著性差异和p值。p值并不代表效应的尺度。更好更常用的方法使报告置信区间。虽然该值是从相同的假设测试或p值计算过程中得出的,但是它对效应的尺度及其不确定性都给出了描述。
例子
以下列出一些有名的统计检定方法以及可供验证实验数据的程序
Student t检定注:Students为发展出此方法原创者的笔名。
变异数分析
卡方分配
费雪最小显著差异法(Fisher"s Least Significant Difference test)
曼-惠特尼U检定(Mann-Whitney U)
回归分析
相关性
皮尔逊积矩相关系数
史匹曼档次相关系数
统计学的范畴
概率论与数理统计
抽样与抽样分布
统计数据的搜集、整理与显示
参数估计
非参数估计
假设检验
方差分析
时间序列分析
统计指数
聚类分析与判别分析
主成分分析与因子分析
相关分析与回归分析
延伸学科
有些科学广泛的应用统计的方法使得他们拥有各自的统计术语,这些学科包括:
农业科学
生物统计
商务统计
数据采矿(应用统计学以及图形从数据中获取知识)
经济统计学
电机统计
统计物理学
人口统计
心理统计学
教育统计学
统计软件gretl
社会统计(包括所有的社会科学)
文献统计分析
化学与程序分析(所有有关化学的数据分析与化工科学)
运动统计学,特别是棒球以及曲棍球
统计对于商业以及工业是一个基本的关键。他被用来了解与测量系统变异性,程序控制,对数据作出结论,并且完成数据取向的决策。在这些领域统计扮演了一个重要的角色。
统计计算
计算机在20世纪后半叶的大量应用对统计科学产生了极大的影响。早期统计模型常常回避线性模型,但强劲的计算机及其算法导致非线性模型(如神经网络)和新式算法(如广义线性模式、等级线性模型)的大量应用。
计算机性能的增强使得需要大量计算的再取样算法成为时尚,如置换检验、自助法。Gibbs取样法也使得贝叶斯模型更加可行。计算机革命使得统计在未来更加注重“实验”和“经验”。大量普通或专业的统计软件现已面市。
滥用
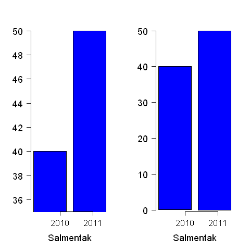
同样的销售量原点不同,看起来差距很大。
统计数据时常被滥用,对结果的解释时常有利于演讲者。 对统计的怀疑与误导可被称为:“世上有三种谎言:谎言,该死的谎言,统计数字”。许多对统计的滥用可能出于无意,也可能出于故意。《如何用统计来说谎》一书( How to Lie With Statistics ) 揭露了许多类似诡计,并在统计的应用与滥用中,回顾了许多案例中的统计方法(e.g. Warne, Lazo, Ramos, and Ritter (2012)。
预防统计滥用包括使用合适的图表、规避偏差。 当结论被轻率概化,超过了它所能代表的范围时,滥用就出现了。这常常是因无意或故意忽视样本偏差所导致的。 条形统计图可能是最容易使用、最容易理解的图表了,它可以用手或计算机绘制而成。 不巧的是,许多人忽视其中的偏差、误差,因为他们不留意。因此,虽然图表质量低劣,但人们常常愿意去相信。 只有当样本可以代表总体时,统计结果才是可信、精确的。 哈弗(Huff)称:“样本的可靠性可以被偏差破坏...给你自己点怀疑的空间吧。”
外部链接
参见
统计学家列表
统计学主题列表
统计图形
免责声明:以上内容版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。感谢每一位辛勤著写的作者,感谢每一位的分享。

相关资料




- 有价值
- 一般般
- 没价值















推荐阅读

关于我们

APP下载


