






记录
关联键
一条记录可能有零个或多个关联键。关联键是以记录其中一个或多个字段的集合,来作为标识符。唯一的键通常被称为主键,或简称为记录键。例如,员工档案可能包含了员工编号,姓名,部门代码和薪资,那么员工编号在组织中应该是唯一的,并且为主键。依据存储媒介和档案结构,员工编号可被编入索引档,另外个别地储存能使查询过程加速。部门代码或许不是唯一的,它也可能被编成索引;这样子它会被当作是次要键或备用键。如果没有索引,则必须依序扫描整个员工档案,以产生特定部门的所属员工列表。薪资领域通常不被视为可用的关键。索引是设计资料档时需考量的一个因素。
历史
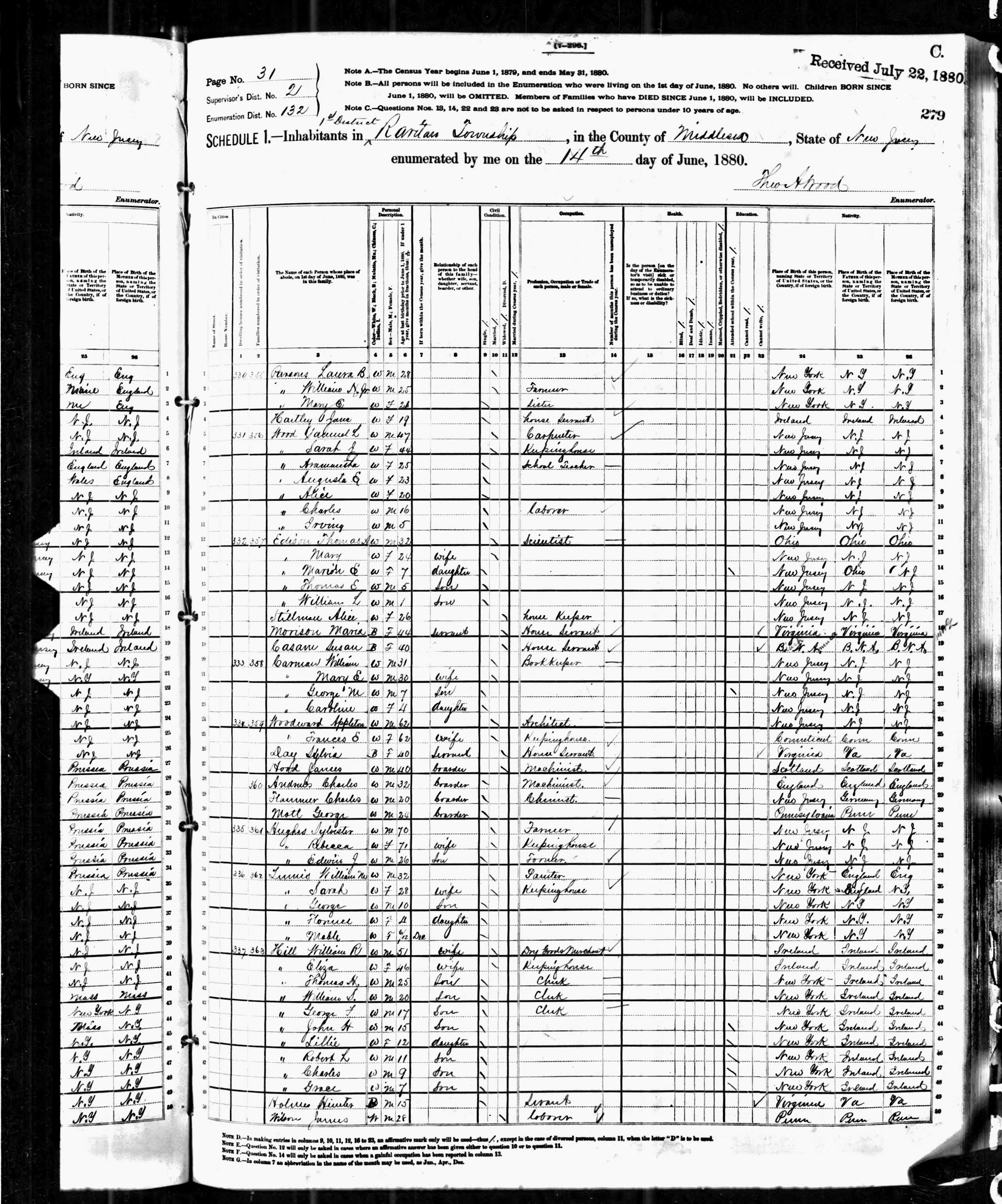
Journal sheet from 1880 United States Census, showing tabular data with rows of data, each a record corresponding to a single person.
记录的概念可从久远的会计使用中回溯到各种类型的表格和分类帐。现代计算机科学中的记录形式,具有明确的类型和大小的字段,已经隐含在19世纪机械的计算器,如巴贝奇的分析机中。

Hollerith punched card (1895)
最初用于处理资料(与控制相反)的机器可读媒介,是在1890年美国人口普查中用于记录的打孔卡:每张打孔卡是单个记录。若将1895年的打孔卡与1880年的日记账两相比较,记录在20世纪上半叶成熟,大多数资料处理是用打孔卡片完成的。通常资料档的每条记录会记录在一张打孔卡中,特定栏分配给特定字段。一般地,记录是可从外部存储装置(例如读卡器,磁带或磁盘)读取的最小单元。
大多数机器语言实现和早期组合语言没有记录的特殊语法,但借由使用索引暂存器,间接定址和自修改代码,这个概念是可用的(并广泛被使用)。一些早期的计算机如IBM 1620,具备了对分隔记录和字段的硬件支援,以及复制这些记录的特殊指令。
一些早期的档案排序和制表工具如IBM的报告程序生成器(Report Program Generator, RPG)中,记录和字段是其核心概念。
COBOL是第一个支持记录类型并广泛使用的编程语言,其记录定义在当时已相当复杂。它允许以任意大小和精度的英数字、整数和小数字段,来定义巢状记录,并自动格式化将值指定给纪录的字段(例如,插入货币符号,小数点和数字组分隔符)。每个档案与读取或写入的资料一并关联到一个记录变量。 COBOL 还提供了一个 MOVE CORRESPONDING 陈述语句,根据名称来指派两个记录的相对应字段。
早期开发用于数值计算的计算机语言,如FORTRAN(到FORTRAN IV)和Algol 60,并不支援记录类型;但这些语言的更新版本,如Fortran 77和Algol 68增加了记录类型。最初的Lisp编程语言也缺乏记录(除了内置的cons单元),但它的S表达式能满足对纪录的需求。将记录类型与其它基本类型完全整合逻辑上一致性的型别系统,则是Pascal编程语言。
PL/I编程语言提供了COBOL格式的记录。C编程语言最初将记录类型( struct )当作是置于储存区块之上的模板概念,而并不是真实的记录资料类型。后来C语言提供了(以 typedef 宣告),但这两个概念在语言上仍然是不同的。在Pascal之后设计的大多数语言(如 Ada,Modula 和 Java)也都支援了记录。
纪录的操作
新记录类型的宣告,包括每个字段的位置,型别和(可能)名称;
将变量和值声明为已定义的记录类型;
从给定的字段值和(有时)字段名称来建构一条记录;
以明确名称来选取一条记录的字段;
将值指定给记录变量;
比较两条记录的等同性;
计算记录的标准杂凑值。
从记录中选取一个字段会产生一个值。
有些语言提供列举记录所有字段的功能,或至少是引用的字段。该功能需要实现某些服务, 像是除错器、垃圾收集器和序列化。它需要具备一定程度的多型。
在具有记录子类型的系统中,记录类型的值操作还可以包括:
增添新字段到记录,设定新字段的值。
从记录中删除一个字段。
在这样的设定中,特定的记录类型表示目前有特定的一组字段,但是该类型的值可能包含其它字段。 因此,具有 x , y 和 z 字段的记录将属于具有 x 和 y 字段的记录类型,以及具有 x , y 和 r 字段的记录。 理由是将( x , y , z )记录传递给某个函数,若该函数预设使用( x , y )记录作为参数,因为该函数将在记录中 找到所需的全部字段。实际上在编程语言中实作记录的许多方法,若允许这样的型别转换会遇到麻烦, 然而在理论中这个事实是记录类型的核心特征。
赋值与比较
大多数语言允许在完全相同类型的记录之间进行指派(包括相同的字段类型和名称,以相同的顺序)。 然而,依照语言的不同,两个单独定义的记录类型,即使它们具有完全相同的字段,也可能被视为不同类型。
在记录之间,有些语言也允许对其中不同名称的字段进行指派,按照字段在其记录中的位置, 将每个字段值与相应的字段变量进行对应;所以譬如有一复数的纪录,其中有 real 和 imag 两个字段, 则可将两字段值指派给有 X 和 Y 字段,表示平面上一点的记录变量。在这种方案中,两个操作数仍旧 要求相同的字段类型序列。
某些语言可能也要求相对应的类型,应该具有相同的大小和编码,以便整个记录能被指派成 不解译的位元字串。而其它语言可能在这方面更有弹性,仅要求每个值字段可合法地指派给 相应的变量字段;所以譬如可将短整数字段分配给长整数字段,反之亦然。
另外的语言(例如COBOL)可借由名称来匹配字段与值,而不用位置。
以上所述的功能性质同理应用在比较两个记录值的等同性。某些语言也允许使用 根据单一字段的字典序来进行次序的比较("")。
PL/I允许以上两种类型的赋值,也允许结构表达式,如 a = a + 1; 其中“a”是一条记录,或是在PL/I术语中所指的结构。
ALGOL 68的字段选取
在Algol 68中,如果 Pts 是一组记录,每个都有整数字段 X 和 Y ,可以写入 Pts.Y 来获得一个整数数组, 由 Pts 的所有元素的 Y 字段组成。结果,语句 Pts[3].Y:=7 和 Pts.Y[3]:= 7 将具有相同的效果。
PASCAL中的WITH陈述句
在Pascal编程语言中,使用 with R do S 的陈述将执行指令序列 S ,就像记录 R 的所有字段都被声明 为变量一样。 所以不必全部写出 Pt.X := 5; Pt.Y := Pt.X +3 ,而可以缩写为 with Pt do begin X := 5; Y := X +3 end 。
在内存中的表现
记录在内存中的表现取决于编程语言。通常,这些字段会依照在记录类型中宣告的相同顺序,连续地储存于内存中。这可能导致两个或多个字段储存在相同的内存字组中;实际上,此功能经常用于系统编程以存取字组的特定位元。另一方面,大多数编译器会添加开发人员看不见的填补字段,以符合硬件要求的对齐限制 -比如浮点字段必须补满整个字组。
有些语言将记录实作为位址指向字段(可能的名称和/或类型)的阵列。面向对象语言中的物件通常以相对复杂的方式实现,特别是在允许多重类别继承的语言中。
自定义纪录
自定义记录是一种类型,其中包含辨别记录类型和记录内定位的相关资讯。它可能包含了元素的偏移量;因此,元素可用任何次序储存或者可省略掉次序。另外在这样类型的记录中,具有标识符的各种元素可简单地依任何次序,跟随彼此。
范例
以下显示记录定义的示例:
PL/I: declare 1 date, 2 year picture "9999", 2 month picture "99", 2 day picture "99";
C: structdate{intyear;intmonth;intday;};
Rust: structDate{year: u32,month: u32,day: u32,}
免责声明:以上内容版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。感谢每一位辛勤著写的作者,感谢每一位的分享。


- 有价值
- 一般般
- 没价值
















推荐阅读

关于我们

APP下载


