






CYK算法
相关参数定义
G = ( V , Σ Σ --> , S , P ) {\displaystyle ~G=(V,\Sigma ,S,P)} 是一个上下文无关文法
对于任意字符串 w = σ σ --> 1 . . . σ σ --> n ∈ ∈ --> Σ Σ --> ∗ ∗ --> {\displaystyle w=\sigma _{1}...\sigma _{n}\in \Sigma ^{*}} ,定义 w [ i , j ] = σ σ --> i . . . σ σ --> j , 1 ≤ ≤ --> i ≤ ≤ --> j ≤ ≤ --> n {\displaystyle w[i,j]=\sigma _{i}...\sigma _{j},~1\leq i\leq j\leq n}
对于任意选择的 i , j {\displaystyle ~i,j} ,定义 V i , j = { X ∈ ∈ --> V | X ⇒ ⇒ --> ∗ ∗ --> w [ i , j ] } {\displaystyle V_{i,j}=\{X\in V~|~X\Rightarrow ^{*}w[i,j]\}}
算法描述
简介
通过由下而上的方法计算 V i , j {\displaystyle ~V_{i,j}} 这个集合,如果 S ∈ ∈ --> V 1 , n {\displaystyle S\in V_{1,n}} ,那么就说明 w {\displaystyle ~w} 是被上下文无关文法 G {\displaystyle ~G} 接受的字符串。
因为 G {\displaystyle ~G} 是一个乔姆斯基范式,当且仅当有下面描述的情况时 X ∈ ∈ --> V i , j {\displaystyle X\in V_{i,j}} :
i Y , Z , k : X → → --> Y Z {\displaystyle i 是 G {\displaystyle ~G} 中的一个规则且 Y ∈ ∈ --> V i , k , Z ∈ ∈ --> V k + 1 , j {\displaystyle Y\in V_{i,k},Z\in V_{k+1,j}}
伪代码
扩展CYK算法
简介
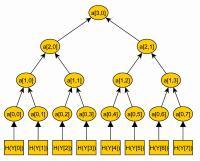
对于上述CYK算法作一个小改动,也就是说记住每次的k,就可以自动产生一个由该上下文无关语言的推导树。
伪代码
通过对下面的方法递归运行就可以生成推导树。
例子
给定一个乔姆斯基范式的上下文无关文法 G = ( { S , A , B , C } , { a , b } , S , P ) {\displaystyle ~G=(\lbrace S,A,B,C\rbrace ,\lbrace a,b\rbrace ,S,P)} ,其中规则 P 如下:
问:字符串 bbabaa 能不能通过该文法产生?
CYK算法可以通过一个表格来运算,表中 i 列 j 行表示由哪几个非终结符可以产生字字符串 σ σ --> i … … --> σ σ --> j {\displaystyle \sigma _{i}\dots \sigma _{j}} 。
如果在表格的最左下角一格中有文法的开始非终结符 S ,那么字符串 bbabaa 就能由上面给出文法 G 产生。
相关链接
Interaktives Java-Applet zur Demonstration
参考文献
John Cocke and Jacob T. Schwartz (1970). Programming languages and their compilers: Preliminary notes. Technical report, Courant Institute of Mathematical Sciences, New York University.
T. Kasami (1965). An efficient recognition and syntax-analysis algorithm for context-free languages. Scientific report AFCRL-65-758, Air Force Cambridge Research Lab, Bedford, MA.
Daniel H. Younger (1967). Recognition and parsing of context-free languages in time n. Information and Control 10(2): 189–208.
免责声明:以上内容版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。感谢每一位辛勤著写的作者,感谢每一位的分享。


- 有价值
- 一般般
- 没价值









24小时热门







推荐阅读

关于我们

APP下载


