






微架构
和指令集架构的关系
指令集架构是指在处理器内被处理的程式,指令集架构为组合语言的设计师和编译器所见。指令集架构包含execution model,暂存器,地址以及资料格式。微架构包含处理器内部的构成以及这些构成起来的部分如何执行指令集架构。微架构通常被表示成流程图,以描述机器内部元件的连结状况,从一个闸或是暂存器,到算术逻辑单元(ALU)。图上分布着资料路径(可以显示资料在微架构的位置)以及控制路径(显示资料该被什么指令所处理)。
每个微架构的的元件都被表示成藉数个逻辑门所建构而成的工具。每个逻辑门都被表示成藉晶体管建构成的零件。拥有不同微架构的机器可能拥有相同的指令集架构,因此可以执行相同的程式。由于半导体科技的进步,新型的处理器可以以较快的速度执行相同的指令集架构。
微架构的概念
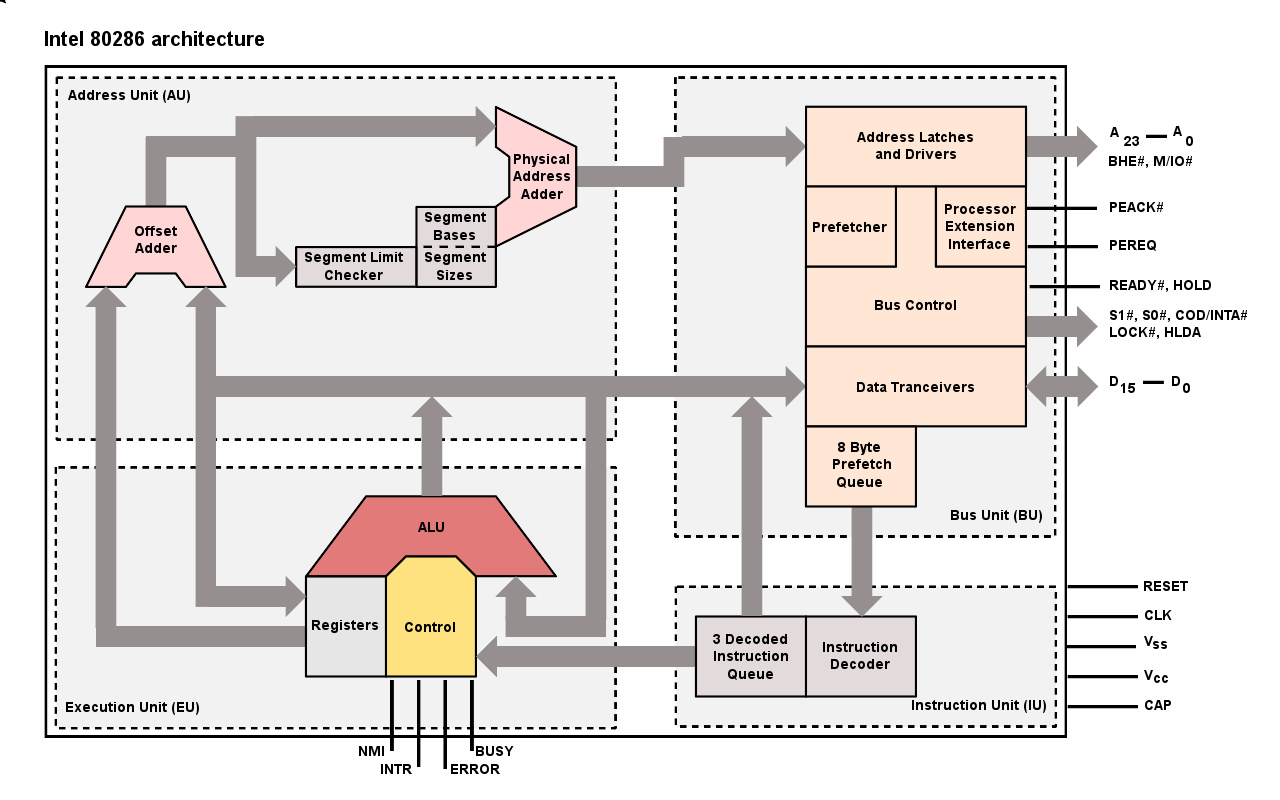
Intel 80286微架构
在今日,管线资料路径是微架构中最常被使用的资料路径。这种作法也被普遍的用于微处理器,微控制器,以及数字信号处理器。管线化的结构允许多个指令在同一时间执行,不同的指令在微架构不同的位置执行。管线分有好几个不同的阶段(stage),这些阶段是微架构的基础。这些阶段包含撷取指令,指令解码,执行指令,以及将资料写回。一些结构还包含其他阶段,像是对内存做存取的动作。管线是微架构其中一项主要的工作。执行单元也是微架构的基本元件。执行单元包含算术逻辑单元(ALU),浮点运算器(FPU),load/store单元,分支预测,以及SIMD。这些单元在处理器内进行计算。执行单元的数量,他们的latency(内存存取资料的时间)及throughput(将资料存到或是读取出内存的速度)影响微架构的效能。
指令周期
所有的中央处理器,微处理器借由以下的步骤来执行程式:
读取指令并将其解码
找到需要用到的资料以执行指令
执行指令
将结果写回
指令周期将会不断循环,直到电力用尽。
执行速度
上面的步骤看起来简单,但阶层内存使这些步骤变得复杂,阶层内存包含快取,主内存,以及非挥发性的内存,例如硬盘(这是指令和资料储存的地方),总是比处理器处理资料的速度慢。步骤(2)常常导致lengthy(在CPU内)delay,这种延迟是在资料通过总线时产生。一直以来,一个不变的目标是在同一时间内执行更多指令,以提升程式执行的效率。这导致逻辑和电路设计变得更复杂。一开始,只有大型电脑和超级电脑使用这种技术,因为这种技术需要大量的电路。当半导体产业发展起来后,这样的技术被加装在单一的半导体芯片上。详见摩尔定律(集成电路可容纳的晶体管数量,每二年增加一倍)。
指令集的选择
指令集从过去以来不断的变化,从一开始的简单到后来的复杂。最近,load-store结构,VLIW以及EPIC是最普遍的指令集。结构处理data parallelism的方法包括SIMD以及向量。一些指令集,例如CISC;多早期的装置使用"CISC"。
然而,对指令集架构的选择可能会对实作高效能的机器产生大的影响。发展RISC处理器是一个好的策略,可以将指令给简化。这样的指令容易在管线内被撷取,解码与执行,由于指令频繁的被使用,快取便被频繁的使用,这样就使内存存取的时间降低。
流水线(pipeline)
在目前,能够最有效的提升效能的方法就是流水线。早期的处理器是等一个指令执行完所有步骤后,然后才轮到下一个指令执行。大部分的电路在某一个步骤结束后就处在闲置的状态,例如,对指令进行解码的电路在指令进入执行阶段后就处于闲置状态。
流水线化的电路借由允许多个指令在同一时间,在电路上不同的位置进行不同的工作。例如,处理器可以在最后一个指令等待结果写回时对另一个指令解码。这使得处理器在同一时间可以处理四个指令,使处理器的效能增加了四倍。
RISC借由将每个阶段分割清楚并让每个阶段都花费一样的时间执行来让管线变小和变得容易建构—每个阶段花费1个cycle的时间。处理器使用了有如工厂装配线的设计,当指令由一边进来的同时就有另一个指令从另一边出去。由于RISC流水线是降低复杂度的设计,使得流水线核心跟指令快取可以被装置在同一个芯片内,这是精简指令集较为快速的原因。早期的装置,例如SPARC和MIPS比Intel和Motorola的CISC还快10倍。
与指令集架构的关系
指令集架构大致上和处理器的程式设计模型(programming model)一样。指令集架构包括执行模型(execution model),暂存器(Processor register),位址和数据格式等。微架构包括处理器的组成部分和对指令集架构的连接和操作。一个系统的微架构通常以描述不同微架构组成部分如何互相连接的平面图代表,而这些微架构组成部分可以是简单的逻辑门(Logic gates),电阻,或是算术逻辑单元(Arithmetic logic unit ,ALU)等大型元件。这些平面图通常把数据路径(Data path)和控制路径(control path)分开。每个组成部分会以示意图表达他们和执行他们的逻辑门之间的连系。
几种典型的微架构
INTEL
Larrabee
P5
P6
NetBurst
Core/Penryn
Bonnell/Saltwell
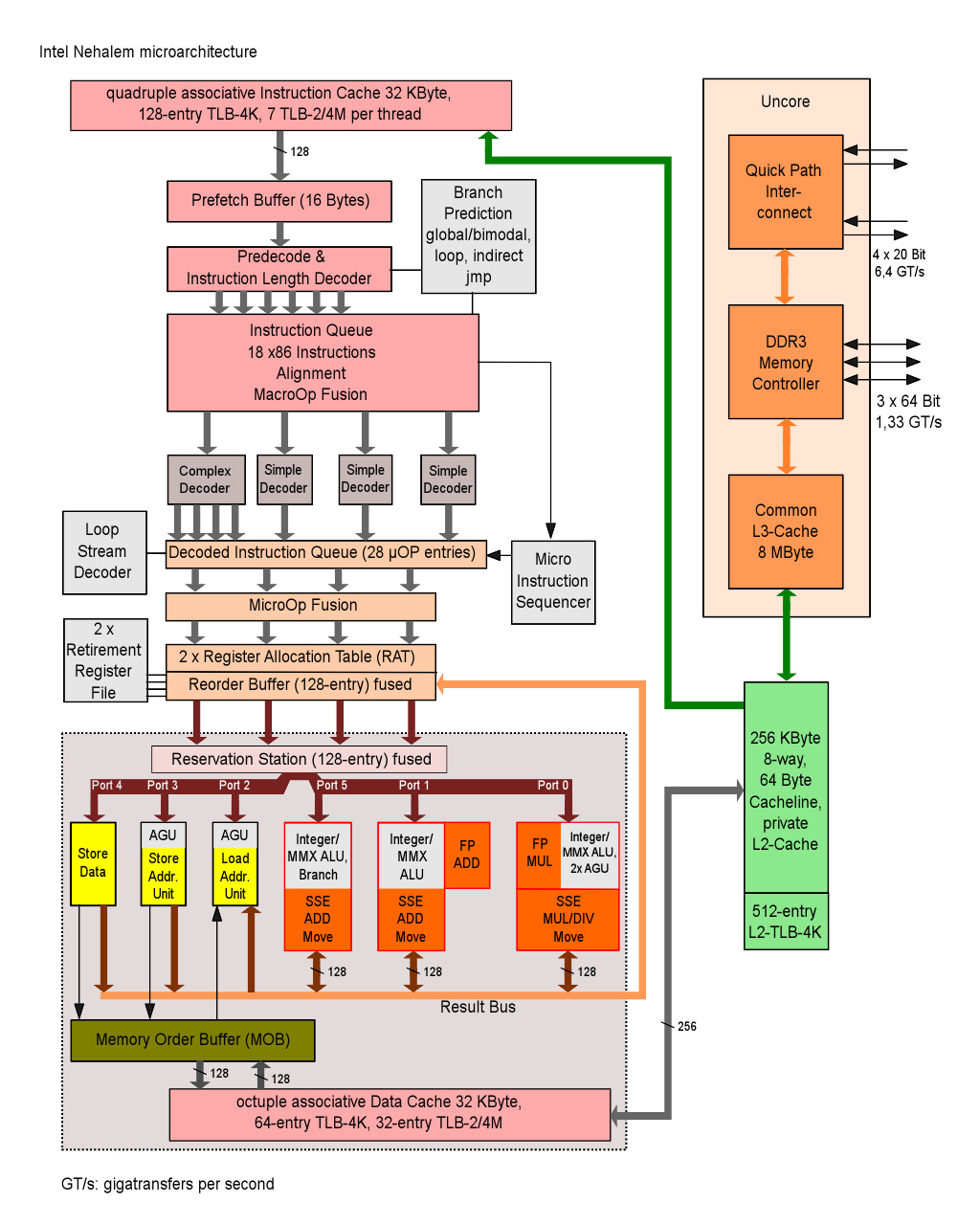
Nehalem/Westmere
Sandy Bridge/Ivy Bridge
Haswell/Broadwell
Skylake/Skymont
AMD
K5 - AMD的首个原创微架构。K5基于Am29000的微架构,并且添加了一个x86的解码器。即使这个设计的原理和Pentium Pro相同,而实际性能更像是Pentium。
K6微架构
K6 - K6并非基于K5,而是基于当时已经被AMD所收购了的NexGen所设计的Nx686处理器,K6的针脚兼容Intel Pentium。
K7微架构
K7 - 是AMD Athlon和Athlon XP的微架构。
K8 AMD的内部代号为Hammer或者SledgeHammer。K8的CPU基于K7,而计算机字增加到了64位,添加了一个集成存储器控制器(integrated memory controller),采用超线程通信结构(HyperTransport communication fabric),二级缓存L2增加到了1MB(1128 KB),增加了SSE指令集。后期的K8增加了SSE3。K8是首个兼容64位Windows的微处理器,在2003年4月22日上市。超线程通信结构(HyperTransport communication fabric)取代了传统的前端总线(Font-side bus),让CUP直接和主存(main memory)链接,
Dual core K8 - 双核心的 Athlon 64 X2在K9被宣布取消后,被错误地称为K9。
被取消。
K10微架构 - 代号为Barcelona ,是AMD系列的第十代微架构,内置四个核心,共享Level 3 Cache第三级缓存,128位浮点单元,AMD-V Nested Paging virtualization和HyperTransport 3.0。
Griffin处理器核心 - Griffin的设计只是用于移动平台(AMD mobile platform),应用于Turion 64处理器。Griffin在2008年发布于Puma平台(Puma platform英语)。Griffin基于65nm制程的K8版本G(K8 revision G),特别对移动市场的需求使用了能源最优化技术(power optimization technologies)。事实上,Griffin的能源最优化技术超越了其他AMD系列第十代微架构。
Bulldozer - 是继K10之后,使用AMD M-SPACE模块化设计方法(modular design methodology)的下一代微架构。Bulldozer是为功耗在10W至100W类别的处理器而设计,应用了XOP(英语), FMA4(英语)和 CVT16(英语)指令集,并且能结合GPU核心(AMD Fusion)。
Bobcat处理器核心 - Bobcat是AMD Bulldozer能源功耗在1W至10W的版本,这个微处理器核心是一个非常精简的x86核心。和Bulldozer相同,Bobcat属于“AMD融合项目”(the AMD Fusion project),能够和GPU组合使用。
微架构的发展方向
这是一个未完成列表。欢迎您扩充内容。
参考文献
《计算机科学技术百科全书》(第二版). 作者:张效祥. 出版社:清华大学出版社,2005年. ISBN:7302105944, 9787302105947
参见
AMD CPU微架构列表
指令集架构
免责声明:以上内容版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。感谢每一位辛勤著写的作者,感谢每一位的分享。


- 有价值
- 一般般
- 没价值
















推荐阅读


关于我们

APP下载


