






二级结构
类型
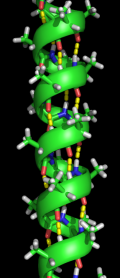
氢键(黄色点)稳定一个α-螺旋
蛋白质的二级结构包含局部残基之间由氢键所调节的相互作用。最普遍的二级结构就是α螺旋及β折叠。经计算后发现其他螺旋,例如3 10 螺旋及π螺旋,在能量上有着有利的氢键模式,但这些螺旋却是在自然的蛋白质中是很稀有的,要α螺旋在中央进行不利的骨架包装后,才可在末端中发现。紧的转角、松开及灵活的环会连结更多“规则的”二级结构。任意形并非真正的二级结构,但却是一类缺乏规则的二级结构的形态。
氨基酸在形成不同的二级结构上有着不同的能力。脯氨酸及甘胺酸会在转角上出现,并且可以瓦解α螺旋骨架的规则形态,但两者却有着不正常的形态能力。在蛋白质内采用螺旋形态的氨基酸有蛋氨酸、丙氨酸、亮氨酸、谷氨酸及赖氨酸(氨基酸单字母编号为“MALEK”);相反,大型的芳香性残基(色氨酸、酪氨酸及苯丙氨酸)及C 分枝的氨基酸(异亮氨酸、缬氨酸及苏氨酸)则采用β折叠形态。但是,若单以序列来看,这些都不足以构成一个可靠的方法来预测二级结构。
DSSP编号
DSSP是“Dictionary of Protein Secondary Structure”的缩写,它是一编文章正式列出已知三维结构的蛋白质二级结构。DSSP编号一般是用单一英文字母来描述蛋白质二级结构。 二级结构是根据氢键模式来指定的。
G:3转角螺旋(亦即3 10 螺旋)。最短长度为3个残基。
H:4转角螺旋(α螺旋)。最短长度为4个残基。
I:5转角螺旋(π螺旋)。最短长度为5个残基。
T:氢键转角(3、4或5个转角)。
E:平行的β折叠,或/及反平行的折叠形态(延伸链)。最短长度为2个残基。
B:独立β桥内的残基(一对β折叠氢键)
S:弯曲(唯一非氢键的指定)
所有不是以上形态的残基,在DSSP都是以空格来指定的,而有时则以C来代表卷曲或L来代表环。螺旋(即G、H及I)及折叠形态都需要一定的长度。这即是指两个在一级结构邻接的残基必须形成相同的氢键模式。如果螺旋或折叠的氢键模式太短,就会分别以T或B来编码。当中亦有其他蛋白质二级结构编号,但却较少使用。
DSSP氢键定义
由于二级结构是以氢键来定义,所以氢键的正确定义十分重要。DSSP内二级结构的标准氢键是一个纯粹静电模型。对于羰基的碳及氧,指定的电荷分别为:
而对于氨基的氮及氢,指定的电荷则分别为:
而静电能是:
根据DSSP,一个氢键只有在E少于-0.5 kcal/mol才会存在。虽然上述的方程式都只是一个相对于氢键能量的估算,但都一般接受作为定义二级结构的工具。
蛋白质二级结构预测
早期蛋白质二级结构预测的方法是建基于氨基酸形成螺旋或折叠的倾向,而有时须联同估计形成二级结构的能量的方法来使用。这些方法在预测残基的三种状态(螺旋、折叠或卷曲)可以有约60%的准确性,若使用多重序列比对可以将准确性大幅提升至80%。多序列比对可以知道氨基酸在某一位置的完正分布(包括在其附近的位置,一般在每一边的7个残基),而演化过程提供了结构趋向更明确的图画。例如,在蛋白质某位置的甘胺酸,本身已表明那是一个任意形。但是多序列对比可以发现,在接近十亿年演化后95%的蛋白质中,那是一个有利螺旋的氨基酸。再者,若在那位置检测平均疏水性,亦会发现其残基可溶性是与α螺旋一致。综合来说,这些因素显示原先蛋白质内甘胺酸是α螺旋结构,而非任意形。多种方法都会结合已有的数据来组成三种状态的预测,这些方法有神经网络、隐马尔可夫模型及支持向量机。现代预测方法亦可在每一个位置的预测结果提供信赖分数。
二级结构预测方法一直不断地在校准,例如EVA实验。基于约270个星期的测试,最准确的方法要算是PsiPRED、SAM、PORTER、PROF及SABLE。有趣的是,在这多种方法中找出共识或一致,并不能提升它们的准确性。最大改善的地方似乎是在β股的预测,因为所使用的方法会忽视一些β股段。整体上而言,最高的预测准确性只可以达90%,因DSSP的标准方法的性质,与校准的预测相违背。
准确的二级结构预测是三级结构预测的重要原素。例如一个确定的βαββαβ二级结构模式,就是铁氧化还原蛋白的记号。
核酸
核酸亦有二级结构,大部分都是单股核糖核酸(RNA)分子。RNA二级结构可以分为螺旋(紧接的碱基对)及不同种类的环(被螺旋围绕的不成对核苷酸)。茎环结构是一个碱基对螺旋结构,末端为短少的不成对环。这种茎环结构非常普遍,并且是建构大型结构模体,如三叶草结构(即如在转运RNA中的四个螺旋结点)的基本单位。内环结构(在长碱基对螺旋中的短而不成对碱基)及膨出(在螺旋股中额外插入,但却在相对股中没有配对的碱基)亦很经常会出现。最后,伪结及base triples亦会出现在RNA。
由于RNA二级结构差不多全都是由碱基对作为中介,它可以说是确定在一个分子或复合物中哪些碱基成对。但是,传统的华生—克里克碱基对并非唯一在RNA的配对方法,霍氏配对方法亦很普遍。
RNA二级结构预测
生物信息学的其中一种应用是使用预测的RNA二级结构来搜寻用作RNA功能形式而非编码的基因组。举例来说,小分子RNA有着由小内环中断的长茎环结构。计算可能的RNA二级结构可以用动态规划方法,但是它不能侦测出伪结或是其他碱基对没有全面网罗的情况较通用的方法有随机上下文无关语法。Mfold是一个使用动态规划的网站。
在很多RNA分子,二级结构对RNA正常功能非常重要,有时甚至于较序列重要。这可以帮助用于分析非编码RNA。RNA二级结构可以用电脑来提升预测准确性。 ,而其他生物信息学的应用会使用一些二级结构的概念来分析RNA。
应用
蛋白质及RNA二级结构都可以用在协助多重序列比对。这种比对在加入有关的二级结构资料后,可以变得更为准确。但有时对RNA却不太有用,这是由于RNA碱基对比序列更受到高度保存。一些不能比对一级结构的蛋白质,二级结构有时亦可以找出它们之间的关系来。
内部链接
结构域
蛋白质结构
翻译
结构模体
免责声明:以上内容版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。感谢每一位辛勤著写的作者,感谢每一位的分享。


- 有价值
- 一般般
- 没价值









24小时热门







推荐阅读

关于我们

APP下载


