






语音识别
历史
早在计算机发明之前,自动语音识别的设想就已经被提上了议事日程,早期的声码器可被视作语音识别及合成的雏形。而1920年代生产的"Radio Rex"玩具狗可能是最早的语音识别器,当这只狗的名字被呼唤的时候,它能够从底座上弹出来 。最早的基于电子计算机的语音识别系统是由AT&T贝尔实验室开发的Audrey语音识别系统,它能够识别10个英文数字。其识别方法是跟踪语音中的共振峰。该系统得到了98%的正确率。 。到1950年代末,伦敦学院(Colledge of London)的Denes已经将语法概率加入语音识别中。
1960年代,人工神经网络被引入了语音识别。这一时代的两大突破是线性预测编码 Linear Predictive Coding (LPC), 及动态时间规整 Dynamic Time Warp 技术。
语音识别技术的最重大突破是隐含马尔科夫模型 Hidden Markov Model 的应用。从Baum提出相关数学推理,经过Rabiner等人的研究,卡内基梅隆大学的李开复最终实现了第一个基于隐马尔科夫模型的大词汇量语音识别系统Sphinx。 。此后严格来说语音识别技术并没有脱离HMM框架。
尽管多年来研究人员一直尝试将“听写机”推广,语音识别技术在目前还无法支持无限领域,无限说话人的听写机应用。
模型
目前,主流的大词汇量语音识别系统多采用统计模式识别技术。典型的基于统计模式识别方法的语音识别系统由以下几个基本模块所构成:
信号处理及特征提取模块。该模块的主要任务是从输入信号中提取特征,供声学模型处理。同时,它一般也包括了一些信号处理技术,以尽可能降低环境噪声、信道、说话人等因素对特征造成的影响。
声学模型。典型系统多采用基于一阶隐马尔科夫模型进行建模。
发音词典。发音词典包含系统所能处理的词汇集及其发音。发音词典实际提供了声学模型建模单元与语言模型建模单元间的映射。
语言模型。语言模型对系统所针对的语言进行建模。理论上,包括正则语言,上下文无关文法在内的各种语言模型都可以作为语言模型,但目前各种系统普遍采用的还是基于统计的N元文法及其变体。
解码器。解码器是语音识别系统的核心之一,其任务是对输入的信号,根据声学、语言模型及词典,寻找能够以最大概率输出该信号的词串。
从数学角度可以更加清楚的了解上述模块之间的关系。首先,统计语音识别的最基本问题是,给定输入信号或特征序列 O = { O 1 , O 2 , ⋯ ⋯ --> O n } {\displaystyle O=\{O_{1},O_{2},\cdots O_{n}\}} ,符号集(词典) W = { W 1 , W 2 , ⋯ ⋯ --> , W n } {\displaystyle {\mathcal {W}}=\{W_{1},W_{2},\cdots ,W_{n}\}} ,求解符号串 W = W 1 , W 2 , ⋯ ⋯ --> , W k {\displaystyle W=W_{1},W_{2},\cdots ,W_{k}} 使得:
通过贝叶斯公式,上式可以改写为
由于对于确定的输入串 O {\displaystyle O} , P ( O ) {\displaystyle P(O)} 是确定的,因此省略它并不会影响上式的最终结果,因此,一般来说语音识别所讨论的问题可以用下面的公式来表示,可以将它称为语音识别的基本公式。 W = arg --> max P ( O | W ) P ( W ) {\displaystyle W=\arg \max P(O|W)P(W)}
从这个角度来看,信号处理模块提供了对输入信号的预处理,也就是说,提供了从采集的语音信号(记为 S {\displaystyle S} )到 特征序列 O {\displaystyle O} 的映射 O : S → → --> O {\displaystyle {\mathcal {O}}:S\rightarrow O} 。而声学模型本身定义了一些更具推广性的声学建模单元 μ μ --> = { u 1 , u 2 , ⋯ ⋯ --> , u m } {\displaystyle {\mathcal {\mu }}=\{u_{1},u_{2},\cdots ,u_{m}\}} ,并且提供了在给定输入特征下,估计 P ( O | u k ) {\displaystyle P(O|u_{k})} 的方法。
为了将声学模型建模单元串 U = u 1 , u 2 , ⋯ ⋯ --> , u l {\displaystyle U=u_{1},u_{2},\cdots ,u_{l}} 映射到符号集 W {\displaystyle {\mathcal {W}}} ,就需要发音词典发挥作用。它实际上定义了映射 D : w ∈ ∈ --> W → → --> U {\displaystyle {\mathcal {D}}:w\in {\mathcal {W}}\rightarrow U} 的映射。为了表示方便,也可以定义一个由 W {\displaystyle {\mathcal {W}}} 到 U {\displaystyle U} 的全集 U {\displaystyle {\mathcal笛卡尔}}} 的笛卡尔积,而发音词典 D {\displaystyle {\mathcal {D}}} 则是这个笛卡尔积的一个子集。并且有:
最后,语言模型则提供了 P ( W ) {\displaystyle P(W)} 。这样,基本公式就可以更加具体的写成:
对于解码器来说,就是要在由 W {\displaystyle {\mathcal {W}}} , μ μ --> {\displaystyle {\mathcal {\mu }}} , u i {\displaystyle u_{i}} 以及时间标度 t {\displaystyle t} 张成的搜索空间中,找到上式所指明的 W {\displaystyle W} 。
系统构成
声学特征
声学特征的提取与选择是语音识别的一个重要环节。声学特征的提取既是一个信息大幅度压缩的过程,也是一个信号解卷过程,目的是使模式划分器能更好地划分。
由于语音信号的时变特性,特征提取必须在一小段语音信号上进行,也即进行短时分析。这一段被认为是平稳的分析区间称之为帧,帧与帧之间的偏移通常取帧长的1/2或1/3。通常要对信号进行预加重以提升高频,对信号加窗以避免短时语音段边缘的影响。
常用的一些声学特征
线性预测系数(Linear Predictive Coefficient,LPC):线性预测分析从人的发声机理入手,通过对声道的短管级联模型的研究,认为系统的传递函数符合全极点数字滤波器的形式,从而n时刻的信号可以用前若干时刻的信号的线性组合来估计。通过使实际语音的采样值和线性预测采样值之间达到均方差最小LMS,即可得到线性预测系数LPC。对LPC的计算方法有自相关法(德宾Durbin法)、协方差法、格型法等等。计算上的快速有效保证了这一声学特征的广泛使用。与LPC这种预测参数模型类似的声学特征还有线谱对LSP、反射系数等等。
倒谱系数:利用同态处理方法,对语音信号求离散傅立叶变换DFT后取对数,再求反变换iDFT就可得到倒谱系数。对LPC倒谱(LPCCEP),在获得滤波器的线性预测系数后,可以用一个递推公式计算得出。实验表明,使用倒谱可以提高特征参数的稳定性。
梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCCs)和感知线性预测(Perceptual Linear Predictive,PLP):不同于LPC等通过对人的发声机理的研究而得到的声学特征,Mel倒谱系数MFCC和感知线性预测PLP是受人的听觉系统研究成果推动而导出的声学特征。对人的听觉机理的研究发现,当两个频率相近的音调同时发出时,人只能听到一个音调。临界带宽指的就是这样一种令人的主观感觉发生突变的带宽边界,当两个音调的频率差小于临界带宽时,人就会把两个音调听成一个,这称之为屏蔽效应。Mel刻度是对这一临界带宽的度量方法之一。
MFCC的计算首先用FFT将时域信号转化成频域,之后对其对数能量谱用依照Mel刻度分布的三角滤波器组进行卷积,最后对各个滤波器的输出构成的向量进行离散余弦变换DCT,取前N个系数。PLP仍用德宾法去计算LPC参数,但在计算自相关参数时用的也是对听觉激励的对数能量谱进行DCT的方法。
中文声学特征
以普通话发音为例,我们会将一个字的发音切割成两个部分,分别是声母(initials)与韵母(finals)。而在发音的过程之中,声母转变至韵母是一个渐进而非瞬间的改变,因此我使用右文相关声韵母模式(Right-Context-Dependent Initial Final, RCDIF)作为分析方法,可以更精准的辨识出正确的音节(syllable)。
而根据声母的不同特征,又可以将声母分为下面四类:

左:ㄅ之时频图 右:ㄆ之时频图
爆破音(Plosive):
发音时嘴唇紧闭后,吐出气流制造出类似爆破的声音。其声音震幅变化会先降至极小值后(代表嘴唇紧闭)后在急剧上升,而端视是否有持续送气,倘若有持续送气(aspirated),则震幅可能会有另一个波峰,若无(un-aspirated )则在波峰之后,震幅将有所下降。如:ㄆ与ㄅ便是前述的关系,ㄆ有持续送气,而ㄅ则无。右图左为ㄅ,右图右为ㄆ。
摩擦音(Fricative):
发音时,舌头紧贴硬颚,形成狭窄的通道,气流通过时造成湍流发生摩擦,由此发出声响。由于摩擦音是透过稳定输出气流,使得声音震幅变化相较于爆破音变化幅度较小。如ㄏ、ㄒ 等皆为摩擦音。
爆擦音(Affricate):
此类型的发声模型兼具爆破音与摩擦音的发声特性。其主要发声构造如同摩擦音是由舌头紧贴硬颚使气流通过时产生摩擦的声音。而其通道更加紧密,使得气流会在瞬间冲出,产生出如同爆破音般的特征。如:ㄑ 、ㄔ等。
鼻音(Nasal):
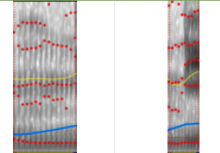
鼻音(ㄋ)之特征
发音时,软颚会下压,下压后,由气管吐出的气流被阻塞,无法进入口腔,因而转往鼻腔。也因此鼻腔与口腔会产生共振,如右图的时频谱上可以明显地看到零点(intensity)分布有共振的现象,而这样的共振现象在右文相关声韵母模式(Right-Context-Dependent Initial Final, RCDIF)下与韵母俩相对较下更加明显。因此,此一现象可作为辨识鼻音(Nasal)的重要依据之一。右图便为鼻音ㄋ之特征,其中红点便为零点(intensity)
而韵母又有双元音、单元音之分,端视再发生时是否有音调的改变。而根据声带振动与否,又分为清音(unvoiced:声带不震动)等差异,以上发音时不同的方式,在时频图上大多可以找到相对应的特征,透过处理二维的时频图,借由传统影像处理的方式,达到语音辨识的目的。
声学模型
语音识别系统的模型通常由声学模型和语言模型两部分组成,分别对应于语音到音节概率的计算和音节到字概率的计算。本节和下一节分别介绍声学模型和语言模型方面的技术。
HMM声学建模:马尔可夫模型的概念是一个离散时域有限状态自动机,隐马尔可夫模型HMM是指这一马尔可夫模型的内部状态外界不可见,外界只能看到各个时刻的输出值。对语音识别系统,输出值通常就是从各个帧计算而得的声学特征。用HMM刻画语音信号需作出两个假设,一是内部状态的转移只与上一状态有关,另一是输出值只与当前状态(或当前的状态转移)有关,这两个假设大大降低了模型的复杂度。HMM的评估、解码和训练相应的算法是前向算法、Viterbi算法和前向后向算法。
语音识别中使用HMM通常是用从左向右单向、带自环、带跨越的拓扑结构来对识别基元建模,一个音素就是一个三至五状态的HMM,一个词就是构成词的多个音素的HMM串行起来构成的HMM,而连续语音识别的整个模型就是词和静音组合起来的HMM。 上下文相关建模:协同发音,指的是一个音受前后相邻音的影响而发生变化,从发声机理上看就是人的发声器官在一个音转向另一个音时其特性只能渐变,从而使得后一个音的频谱与其他条件下的频谱产生差异。上下文相关建模方法在建模时考虑了这一影响,从而使模型能更准确地描述语音,只考虑前一音的影响的称为Bi-Phone,考虑前一音和后一音的影响的称为Tri-Phone。
英语的上下文相关建模通常以音素为基元,由于有些音素对其后音素的影响是相似的,因而可以通过音素解码状态的聚类进行模型参数的共享。聚类的结果称为senone。决策树用来实现高效的triphone对senone的对应,通过回答一系列前后音所属类别(元/辅音、清/浊音等等)的问题,最终确定其HMM状态应使用哪个senone。分类回归树CART模型用以进行词到音素的发音标注。
语言模型
语言模型主要分为规则模型和统计模型两种。统计语言模型是用概率统计的方法来揭示语言单位内在的统计规律,其中n元语法简单有效,被广泛使用。
n元语法:该模型基于这样一种假设,第n个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。由于计算量太大,N一般取值不会很大,常用的是二元语法(Bi-Gram)和三元语法(Tri-Gram)。
语言模型的性能通常用交叉熵和复杂度(Perplexity)来衡量。交叉熵的意义是用该模型对文本识别的难度,或者从压缩的角度来看,每个词平均要用几个位来编码。复杂度的意义是用该模型表示这一文本平均的分支数,其倒数可视为每个词的平均概率。平滑是指对没观察到的N元组合赋予一个概率值,以保证词序列总能通过语言模型得到一个概率值。通常使用的平滑技术有图灵估计、删除插值平滑、Katz平滑和Kneser-Ney平滑。
搜索
连续语音识别中的搜索,就是寻找一个词模型序列以描述输入语音信号,从而得到词解码序列。搜索所依据的是对公式中的声学模型打分和语言模型打分。在实际使用中,往往要依据经验给语言模型加上一个高权重,并设置一个长词惩罚分数。
Viterbi:基于动态规划的Viterbi算法在每个时间点上的各个状态,计算解码状态序列对观察序列的后验概率,保留概率最大的路径,并在每个节点记录下相应的状态信息以便最后反向获取词解码序列。Viterbi算法在不丧失最优解的条件下,同时解决了连续语音识别中HMM模型状态序列与声学观察序列的非线性时间对准、词边界检测和词的识别,从而使这一算法成为语音识别搜索的基本策略。
由于语音识别对当前时间点之后的情况无法预测,基于目标函数的启发式剪枝难以应用。由于Viterbi算法的时齐特性,同一时刻的各条路径对应于同样的观察序列,因而具有可比性,束Beam搜索在每一时刻只保留概率最大的前若干条路径,大幅度的剪枝提高了搜索的效率。这一时齐Viterbi-Beam算法是当前语音识别搜索中最有效的算法。 N-best搜索和多遍搜索:为在搜索中利用各种知识源,通常要进行多遍搜索,第一遍使用代价低的知识源,产生一个候选列表或词候选网格,在此基础上进行使用代价高的知识源的第二遍搜索得到最佳路径。此前介绍的知识源有声学模型、语言模型和音标词典,这些可以用于第一遍搜索。为实现更高级的语音识别或口语理解,往往要利用一些代价更高的知识源,如4阶或5阶的N-Gram、4阶或更高的上下文相关模型、词间相关模型、分段模型或语法分析,进行重新打分。最新的实时大词表连续语音识别系统许多都使用这种多遍搜索策略。
N-best搜索产生一个候选列表,在每个节点要保留N条最好的路径,会使计算复杂度增加到N倍。简化的做法是只保留每个节点的若干词候选,但可能丢失次优候选。一个折衷办法是只考虑两个词长的路径,保留k条。词候选网格以一种更紧凑的方式给出多候选,对N-best搜索算法作相应改动后可以得到生成候选网格的算法。
前向后向搜索算法是一个应用多遍搜索的例子。当应用简单知识源进行了前向的Viterbi搜索后,搜索过程中得到的前向概率恰恰可以用在后向搜索的目标函数的计算中,因而可以使用启发式的A算法进行后向搜索,经济地搜索出N条候选。
系统实现
语音识别系统选择识别基元的要求是,有准确的定义,能得到足够数据进行训练,具有一般性。英语通常采用上下文相关的音素建模,汉语的协同发音不如英语严重,可以采用音节建模。系统所需的训练数据大小与模型复杂度有关。模型设计得过于复杂以至于超出了所提供的训练数据的能力,会使得性能急剧下降。
听写机:大词汇量、非特定人、连续语音识别系统通常称为听写机。其架构就是建立在前述声学模型和语言模型基础上的HMM拓扑结构。训练时对每个基元用前向后向算法获得模型参数,识别时,将基元串接成词,词间加上静音模型并引入语言模型作为词间转移概率,形成循环结构,用Viterbi算法进行解码。针对汉语易于分割的特点,先进行分割再对每一段进行解码,是用以提高效率的一个简化方法。
对话系统:用于实现人机口语对话的系统称为对话系统。受目前技术所限,对话系统往往是面向一个狭窄领域、词汇量有限的系统,其题材有旅游查询、订票、数据库检索等等。其前端是一个语音识别器,识别产生的N-best候选或词候选网格,由语法分析器进行分析获取语义信息,再由对话管理器确定应答信息,由语音合成器输出。由于目前的系统往往词汇量有限,也可以用提取关键词的方法来获取语义信息。
自适应与强健性
语音识别系统的性能受许多因素的影响,包括不同的说话人、说话方式、环境噪音、传输信道等等。提高系统强健性,是要提高系统克服这些因素影响的能力,使系统在不同的应用环境、条件下性能稳定;自适应的目的,是根据不同的影响来源,自动地、有针对性地对系统进行调整,在使用中逐步提高性能(其中以李开复博士的不特定语音识别系统为例)。以下对影响系统性能的不同因素分别介绍解决办法。
解决办法按针对语音特征的方法(以下称特征方法)和模型调整的方法(以下称模型方法)分为两类。前者需要寻找更好的、高强健性的特征参数,或是在现有的特征参数基础上,加入一些特定的处理方法。后者是利用少量的自适应语料来修正或变换原有的说话人无关(SI)模型,从而使其成为说话人自适应(SA)模型。
说话人自适应的特征方法有说话人规一化和说话人子空间法,模型方法有贝叶斯方法、变换法和模型合并法。
语音系统中的噪声,包括环境噪声和录音过程加入的电子噪声。提高系统鲁棒性的特征方法包括语音增强和寻找对噪声干扰不敏感的特征,模型方法有并行模型组合PMC方法和在训练中人为加入噪声。信道畸变包括录音时话筒的距离、使用不同灵敏度的话筒、不同增益的前置放大和不同的滤波器设计等等。特征方法有从倒谱矢量中减去其长时平均值和RASTA滤波,模型方法有倒谱平移。
最大后验概率(Maximum A-posteriori Probability (MAP) Estimate)
最大后验概率估计(maximum a posteriori probability (MAP) estimate)是后验概率分布的众数。利用最大后验概率估计可以获得对实验数据中无法直接观察到的量的点估计。它与最大似然估计中的经典方法有密切关系,但是它使用了一个增广的优化目标,进一步考虑了被估计量的先验概率分布。所以最大后验概率估计可以看作是规则化(regularization)的最大似然估计。
以此为基础的自适性方法有以下特性:
越大的调整测资(adaptation data)可以让结果越接近理想的客制化模型
当调整测资(adaptation data)不足时,无法显著提升模型的精准度
最大相似线性回归(Maximum Likelihood Linear Regression(MLLR) )
MLLR,是一种基于词网的最大似然线性回归(Lattice-MLLR)无监督自适应算法,并进行了改进。是一种基于变换的方法,对数据量依赖较小,常用于数据量较少的情况或进行快速自适应 一种基于词网的最大似然线性回归(Lattice-MLLR)无监督自适应算法,并进行了改进。 Lattice-MLLR是根据解码得到的词网估计MLLR变换参数,词网的潜在误识率远小于识别结果,因此可以使参数估计更为准确。 Lattice-MLLR的一个很大缺点是计算量极大,较难实用。MLLR 是一种基于变换的方法,对数据量依赖较小,常用于数据量较少的情况或进行快速自适应。
以此为基础的自适性方法有以下特性:
在少量的调整测资(adaptation data)可以显著提升模型的精准度
当调整测资(adaptation data)达到一定量后,精准度的提升会进入饱和状态,有明显的效率上界
而最大相似线性回归(Maximum Likelihood Linear Regression(MLLR) )也有许多变形。其中区块对角最大相似线性回归(block-diagonal Maximum Likelihood Linear Regression(MLLR))可以再更少量的调整测资下提升更大的精准度,然而其进入准度的饱和状态也更快,精准度上限也更低。
综合以上,端视调整测资(adaptation data)的多寡,可以选择适当的方法,让模型的精准度最高。
参考文献
^ 语音输入法
^ 5.1 Automatic Speech Recognition (ASR) History, www.icsi.berkeley.edu/eecs225d/spr95/lecture05.ps.gz
^ Davis, Biddulph and Balashek Automatic Recognition of Spoken Digits, Journal of the Acoustical Society of America Vol 24 No 6, November 1952
^ Automatic Speech Recognition: The Development of the Sphinx Recognition System KF Lee, R Reddy - 1988 - Kluwer Academic Publishers Norwell, MA, USA
免责声明:以上内容版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。感谢每一位辛勤著写的作者,感谢每一位的分享。

相关资料




- 有价值
- 一般般
- 没价值















推荐阅读

关于我们

APP下载


