

更多文章
更多精彩文章




 QQ空间
QQ空间
 QQ好友
QQ好友
 微信好友
微信好友
 新浪微博
新浪微博
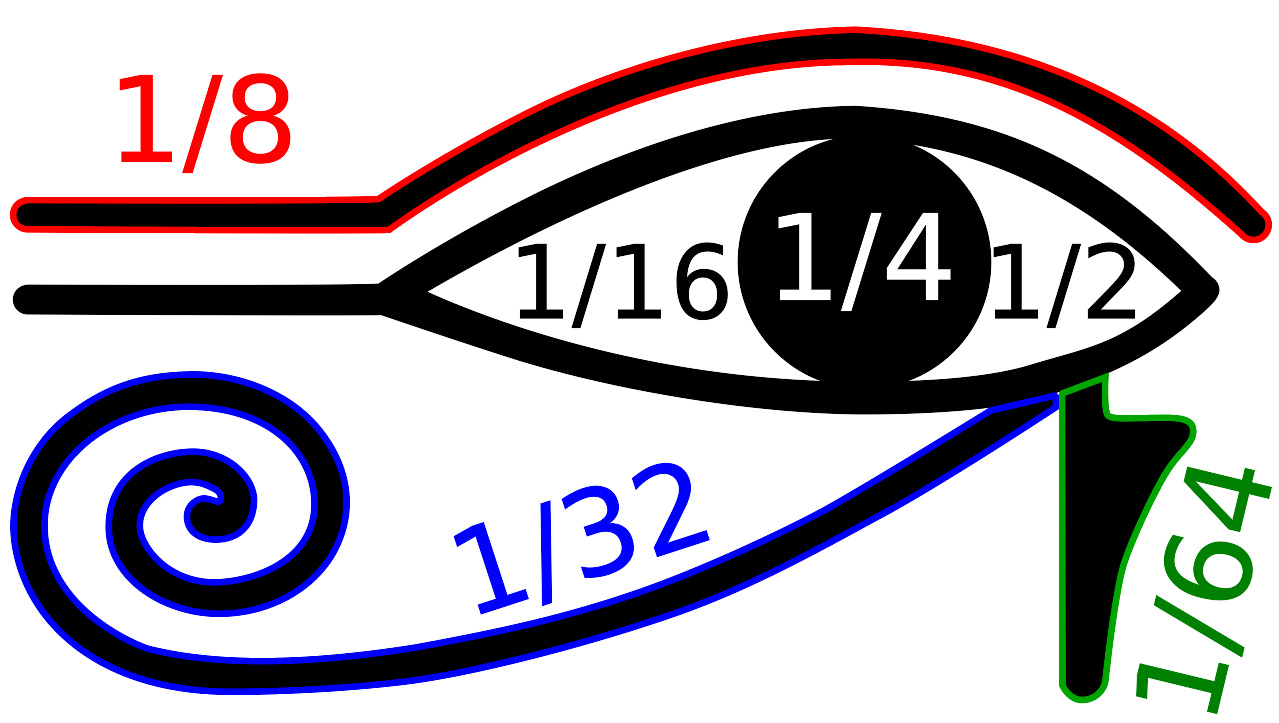
相关条目
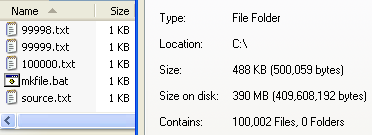
文本文件
电脑文件
base64编码解码
免责声明:以上内容版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。感谢每一位辛勤著写的作者,感谢每一位的分享。




















{{item.time}} {{item.replyListShow ? '收起' : '展开'}}评论 {{curReplyId == item.id ? '取消回复' : '回复'}}